Model intelligence is no longer the constraint for automation
Why automation lags even as models get better

The perception is that model improvement seems to be stagnating. GPT-5 wasn’t the step change that people were expecting. Yet, models continue to improve on reasoning benchmarks. Recently, both OpenAI and Google models were on par with gold medallists in the International Mathematical Olympiad 2025 (IMO). At the same time it’s still difficult to make AI agents work for relatively simple enterprise use cases. Why is there such a disparity in model performance between problem domains? Why are models so much better at complex maths tasks that only few humans can complete, while struggling at simple every day tasks done by most humans?
It’s because the bottleneck isn’t in intelligence, but in human tasks: specifying intent and context engineering.
A mental model for tasks
To understand this, let’s start by defining what is required to solve a task:
1) Problem specification: a precise, detailed definition of the latent intent of a task
2) Context: the local knowledge needed to solve the task
3) Solver: a model with tools that acts on the spec using the context
Every task has an underlying ‘latent intent’ with a complete set of requirements a correct solution should satisfy. A problem specification is an artifact that attempts to communicate this intent in a structured, precise and complete way1. Specifications are often not complete. Let’s call the remaining uncertainty about the intent the specification gap.
When there's a specification gap, the solver will attempt to infer using:
Global priors: general knowledge and capabilities embedded in the model weights; its ‘world model’.
Local context: task-specific information that contextualizes the task (documents, history, notes, etc.).
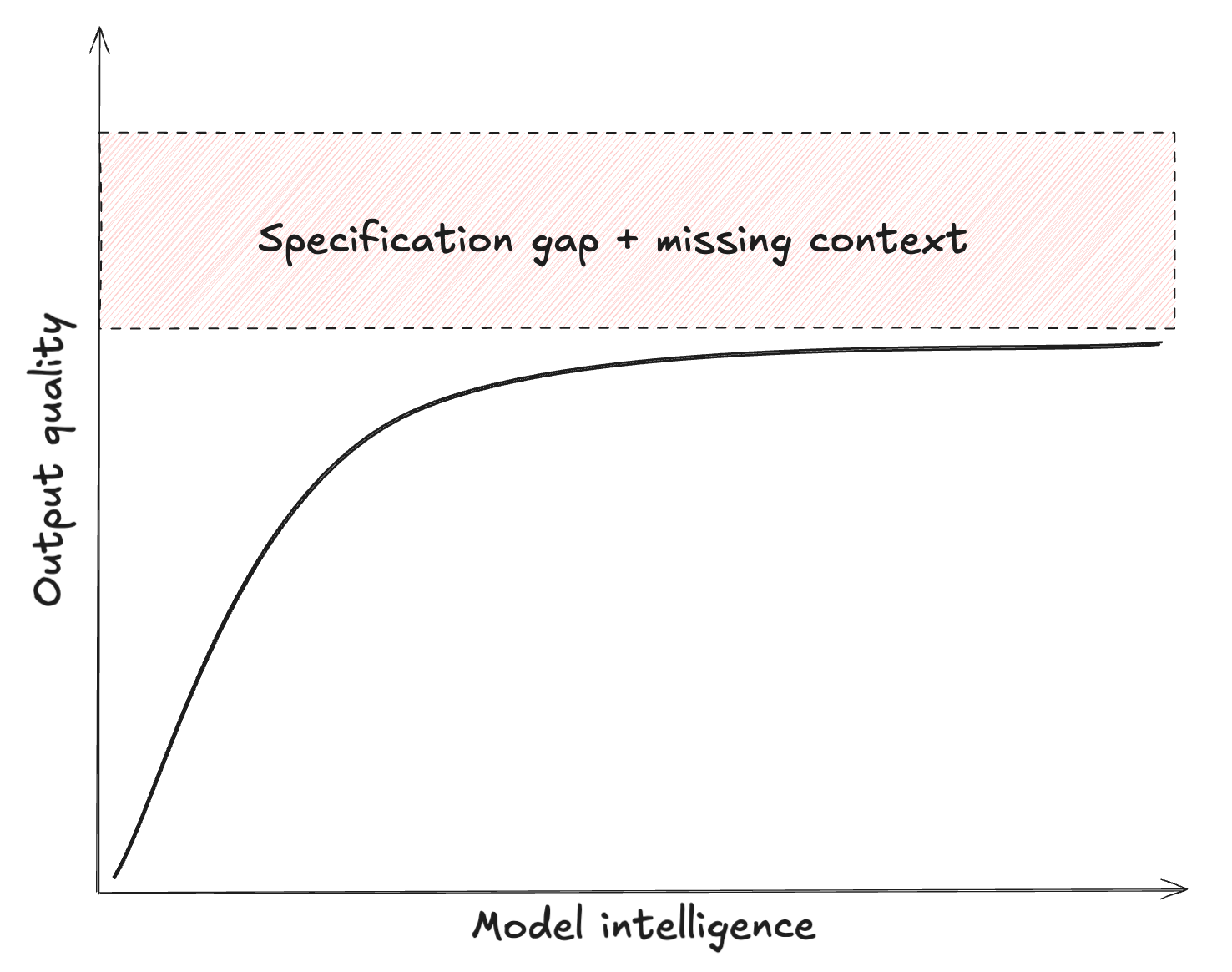
We can express the quality of the model response as:
where the quality is measured by how closely aligned the response is to the user’s intent.
Why math is easy, life is hard
In mathematics we can often write a formally complete specification (‘no specification gap’). Consider for example one of the IMO 2025 problems:
Consider a 2025 x 2025 grid of unit squares. Matlida wishes to place on the grid some rectangular tiles, possibly of different sizes, such that each side of every tile lies on a grid line and every unit square is covered by at most one tile.
Determine the minimum number of tiles Matlida needs to place so that each row and each column of the grid has exactly one unit square that is not covered by any tile.
This statement alone contains all the information necessary to find a correct solution. However, this was the only IMO problem the models couldn’t solve, so clearly the bottleneck for solving this problem is in the model’s intelligence and available tools. In this sense, math is an ‘easy target’ for LLMs to progress on, as we have to optimize only for increasing model intelligence.2
For real world problems, the situation is different. Work tasks live in moving systems. “write a slide deck for a board presentation” is a fuzzy spec; the answer depends on strategy, runway, risks the board cares about, what was said last meeting, the taboo topics etc. That context is scattered in documents, inboxes, and people’s heads. Without context, the model can try to infer an answer creatively, but will likely be off base. To make matters worse, feedback and verification is subjective and slow.
How much better would the answer be if the LLM were 10x ‘smarter’ but would have the same limited context?3 Likely a bit better, but not great. Unfortunately, increasing raw model intelligence only provides an asymptotic improvement in output quality. The quality of the spec and context dominate the outcome. Releasing those constraints is mostly a human task: we have to build better context engines, and write better problem specs.
We can roughly split domains into two, with different bottlenecks:
‘Easy targets’: domains with canonical specs, limited local context, easy verification. Examples: math, coding.
‘Hard targets’: domains with complex and evolving specs, hidden constraints, large noisy context and lack of verification. Examples: product strategy, operations, sales, compliance, most corporate workflows.
Excitingly, a lot of science falls into the ‘easy targets’ bucket. However, most practical use cases of AI fall into the ‘hard targets’ buckets. Therefore, if we want to achieve the goal of significant automation through AI, we need to find ways to tackle the hard targets.
Progressing on ‘hard targets’
Imagine a company run by 90% agents and 10% humans. Most workflows are fully automated. Is that possible with the current generation of LLMs? I don’t think so. Practically, you run into a wall: specs and ‘local context’ pipelines need to be engineered and maintained for every workflow. This scales terribly. For a company with thousands of interdependent workflows, this would require an endless amount of authoring and updating specifications and adapting context pipelines. While AI could help with this, humans are still the bottleneck.
So what would get us to the highly automated future? Near term, there are a few things to progress on the engineering side to enable agents to be more autonomous in finding the right context:
Make context easily accessible. Record hidden context (e.g. meeting transcripts, decisions) and take it out of local silos (e.g. local Excel files). Expose that data accessible through API, and add documentation so agents know what each table means and when it was updated.
Build an intelligent middle layer of episodic memory systems so agents can browse context, discard what is not needed, and save what is relevant. More tooling is needed to not have to repeat large searches for every task, to save previous iterations of tasks and user feedback, and to dynamically add relevant context from memory into prompts.
Upgrade context window length while retaining model performance, so more context can be provided and less engineering has to be done to filter out irrelevant context.
Reducing the human bottleneck
Longer term, we can reduce the human bottleneck by shifting local context from prompts into weights, so agents infer specs the way people do after enough repetitions.
For this to happen, several breakthroughs are required:
Companies need effective ways to capture and structure their internal context (emails, meetings, transcriptions etc.) while filtering out noise to avoid training on junk data.
Train / finetuning custom models should be cheap and secure, since most of the new training data will be private.
Models must continuously learn, updating their internal context to stay up to date with a dynamic environment.
Models need brain surgery. As new models come out, we need the ability to 'git merge' new updates to a model, while retaining weights encoding local context.4
These are real research and architecture problems.
Where this leaves us
I’m bullish on agents for easy targets in the short term. I think we’re going to see mindblowing results in science. I’m cautious about broad corporate automation until we treat specs and context as first-class systems. We know the bottlenecks, and we have some tools to chip away at them, but the infrastructure to handle specs and context at scale is still nascent. There is a lot left to build.
See Sean Grove’s talk for a great explanation of this concept
Additionally, high quality examples of problem specs in maths are easy to find, often contain verifiably correct answers, and generating high quality synthetic data is relatively easy.
That makes you think, what do we mean by intelligence? What does an AI look like that is 10x more intelligent but doesn’t have any context?
See for example https://arxiv.org/abs/2310.16218
Btw, if, as you said, the intelligence of current large models is already sufficient, then GPT-5 clearly wouldn’t fail to distinguish between 5.11 and 5.9. In this case, the model is provided with a clear problem specification and sufficient context. Its world model also contains enough knowledge about how numbers are counted and what each digit represents. As long as its reasoning ability is functioning normally, it should be impossible for it to make such a mistake
ref:http://x.com/TimelessMartian/status/19539
You mentioned in your article that the bottleneck is not the intelligence of the model, but rather problem specification and context. I think this is a bit too optimistic. In fact, when we provide problem specifications and context to humans, they are often neither precise nor complete, yet people can still use their intelligence to infer the missing but necessary information. Or, when their output does not meet our needs, we can give feedback, and they revise their answers. After repeating this process a few times, we usually arrive at a better result. In this respect, models are not at a greater disadvantage than humans. But the current situation is that when a model’s output is unsatisfactory, even if we provide multiple rounds of feedback and additional information, it still fails to reach the level that a human would achieve in the same situation. Many times, humans can solve problems that models cannot, which clearly shows that the model’s intelligence is still insufficient.